Version 4.0.0 (January 4, 2023)
© 2012-2023 Cornutum Project
Contents
- Introduction
- Getting Started
- Modeling The Input Space
- Defining Input Coverage
- Managing A Tcases Project
- Transforming Test Cases
- Further Reference
Introduction
What Does It Do?
Tcases is a tool for designing tests. It doesn't matter what kind of system you are testing. Nor does it matter what level of the system you are testing — unit, subsystem, or full system. You can use Tcases to design your tests in any of these situations. With Tcases, you define the input space for your system-under-test and the level of coverage that you want. Then Tcases generates a minimal set of test cases that meets your requirements.
Tcases is primarily a tool for black-box test design. For such tests, the concept of "coverage" is different from structural testing criteria such as line coverage, branch coverage, etc. Instead, Tcases is guided by coverage of the input space of your system.
What is the "input space" of the system? The simplest way to look at it is this: the set of all (combinations of) input values that could possibly be applied. Easy to say, but hard to do! For all but the simplest systems, such a set is enormous, perhaps even infinite. You could never afford to build and run all those test cases. Instead, you have to select test cases from a small sample of the input space. But how? If your sample is too big, you'll run out of time before you finish. But if your sample is too small — or, worse, if it's the wrong subset — you'll miss lots of defects.
That is the test design problem: given a limited amount of testing effort, how can you minimize the risk of defects? And Tcases is the tool for the job. Tcases gives you a way to define the input space for your system in a form that is concise but comprehensive. Then Tcases allows you to control the number of test cases in your sample subset by specifying the level of coverage you want. You can start with a basic level of coverage, and Tcases will generate a small set of test cases that touches every significant element of the input space. Then you can improve your tests by selectively adding coverage in specific high-risk areas. For example, you can specify pairwise coverage or higher-order combinations of selected input variables.
How Does It Work?
First, you create a system input definition, a document that defines your system as a set of functions. For each system function, the system input definition defines the variables that characterize the function input space.
Then, you can create a generator definition. That's another document that defines the coverage you want for each system function. The generator definition is optional. You can skip this step and still get a basic level of coverage.
Finally, you run Tcases. Tcases is a Java program that you can run from the command line or from your favorite IDE. Tcases comes with built-in support for running using a shell script or an ant target. You can also run Tcases with Maven using the Tcases Maven Plugin. Using your input definition and your generator definition, Tcases generates a system test definition. The system test definition is a document that lists, for each system function, a set of test cases that provides the specified level of coverage. Each test case defines a specific value for every function input variable. Tcases generates not only valid input values that define successful test cases but also invalid values for the tests cases that are needed to verify expected error handling.
Of course, the system test definition is not something you can execute directly. But it follows a well-defined schema, which means you can use a variety of XML transformation tools to convert it into a form that is suitable for testing your system. For example, Tcases comes with a built-in transformer that converts an XML system test definition into a Java source code template for a JUnit or TestNG test class. You can also automatically transform a system test definition into a simple HTML report.
Why Tcases?
- If you are defining acceptance for a new story...
Tcases gives you a powerful technique for crystallizing your understanding of a new story: modeling the input space. This is especially helpful if you are following a behavior-driven development (BDD) process. BDD captures the intended system behavior using a few key examples, each of which is expressed in the form of a test case. BDD examples naturally identify important system input variables. Input modeling then leads to a deeper and broader understanding of the inputs that the system must handle. Quickly creating a high-level system input definition is a great way to check if you've identified all the examples you need.
- If you are building unit tests...
If you are practicing test-driven development (TDD), congratulations! — you are building unit tests to guide the design of your system. But when it comes to actually testing your system — that is, systematically seeking out and removing every defect — your TDD unit tests are almost certainly insufficient. Each TDD unit test is usually built to demonstrate a single specific feature of the system. But a large number of defects (perhaps more than 50%) are caused by interactions among multiple features. (For an interesting discussion of the interactions that cause software failures, see this research study). Even if you've made the effort to create unit tests that produce 100% code coverage, you are still likely to miss many of those interactions between explicit unit inputs and implicit inputs such as internal state variables.
Instead, you need a more powerful approach — like Tcases. By generating test cases from a complete model of all input variables, you can systematically cover interactions among inputs to a specified degree. And you can do it with a small set of unit tests, typically not much more than you would have done with TDD.
- If you are building integration tests or system tests...
Unit tests are not enough to find all of the defects in your system. You also need integration tests and even full system tests. But how many of them do you need? You certainly don't need to replicate the same test cases already covered by your unit tests.
With these higher-level tests, the game has changed. There is a new input space with new dimensions of variation to consider. So you can use Tcases to model these inputs and generate new test cases that cover the interactions among them. For example, system tests often need to consider variations in the settings of key deployment configuration parameters. Tcases gives you a way to gain confidence about the interactions among multiple configuration parameters with a small number of test cases.
Getting Started
About This Guide
This guide explains everything about how Tcases works. And when it comes to examples, this guide shows how to do things when running Tcases as a shell command. If you run Tcases using the Tcases Maven Plugin, the command line details will be slightly different, but all of the concepts remain the same.
Installing The Tcases Maven Plugin
To get dependency info for the Tcases Maven Plugin, visit the plugin documentation site.
Installing The Tcases Distribution
To get the command line version of Tcases, download the Tcases binary distribution file from the Maven Central Repository, using the following procedure.
- Visit the Central Repository search page.
- Search for "tcases-shell".
- You will see the most recent release of "tcases-shell". (To see all N previous versions, select "(N)" under "Latest Version".).
- Use the downward arrow button to select the type of file you want to download. Choose either as a ZIP file or a compressed tar file (tar.gz).
Extract the contents of the distribution file to any directory you like — this is now your "Tcases home directory". Unpacking the distribution file will create a "Tcases release directory" — a subdirectory of the form tcases-m.n.r — that contains all the files for this release of Tcases. The release directory contains the following subdirectories.
- bin: Executable shell scripts used to run Tcases
- docs: User guide, examples, and Javadoc
- lib: All JAR files needed to run Tcases
One more step and you're ready to go: add the path to the bin subdirectory to the PATH environment variable for your system.
XML or JSON?
The choice is yours — Tcases can read and write documents using either XML or JSON data formats. Because XML is the original format used by Tcases, all of the examples in this guide assume you are using XML.
Starting with Tcases 4.0.0, JSON is the preferred format for all Tcases documents, and new features will be supported only for JSON documents. You can find the complete guide to Tcases using JSON here.
You can convert an existing XML project to JSON using the tcases-copy command (or, if using Maven, the tcases:copy goal). For example, the following command will convert myProject-Input.xml and all of its associated project files into the corresponding *.json files.
tcases-copy provides many other options for copying a Tcases project. For complete details, use the -help option.
Running From the Command Line
You can run Tcases directly from your shell command line. If you use bash or a similar UNIX shell, you can run the tcases command. Or if you are using a Windows command line, you can run Tcases with the tcases.bat command file, using exactly the same syntax.
For example, for a quick check, you can run one of the examples that comes with Tcases, using the following commands.
> cd docs/examples/xml
> tcases < find-Input.xml
For details about the interface to the tcases command (and the tcases.bat command, too), see the Javadoc for the TcasesCommand.Options class. To get help at the command line, run tcases -help.
Running With Ant
You can also run Tcases as an Ant task (requires Ant 1.10.9 or later). For an example of how this works, take a look at examples/ant/ant-tcases.xml. Want to try it out? Run the the following commands.
> cd docs/examples/ant
> ant -f ant-tcases.xml
For details about the interface to the tcases task, see the Javadoc for the TcasesTask class.
Understanding Tcases Results
What happens when you run Tcases? Tcases reads a system input definition, a document that defines the "input space" of the system function to be tested. From this, Tcases produces a different document called a system test definition, which describes a set of test cases.
Try running Tcases on one of the example system input definitions. The following commands will generate test cases for the find command example, which is explained in full detail later in this guide.
> cd docs/examples/xml
> tcases < find-Input.xml
The resulting system test definition is written to standard output. Here's what it looks like: for the "find" function, a list of test case definitions, each of which defines values for all of the function's input variables.
<TestCases system="Examples">
<Function name="find">
<TestCase id="0">
<Input type="arg">
<Var name="pattern.size" value="empty"/>
<Var name="pattern.quoted" value="yes"/>
<Var name="pattern.blanks" NA="true"/>
<Var name="pattern.embeddedQuotes" NA="true"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="yes"/>
<Var name="file.contents.linesLongerThanPattern" value="one"/>
<Var name="file.contents.patterns" NA="true"/>
<Var name="file.contents.patternsInLine" NA="true"/>
</Input>
</TestCase>
...
</Function>
</TestCases>
Modeling The Input Space
Tcases creates test definitions based on a system input definition that you create. But how do you do that? That's what this section aims to explain.
A system input definition is a document that models the "input space" of the system-under-test (SUT). We say it "models" system inputs because it doesn't literally itemize all possible input values. Instead, a system input definition lists all the important aspects of system inputs that affect system results. Think of this as describing the "dimensions of variation" in the "input space" of your system. Some dimensions of variation are obvious. If you are testing the add function, you know there are at least two dimensions of variation — the two different numbers being added. But to find all of the key dimensions, you may have to take a deeper look.
For example, consider how you might test a simple "list files" command, like the ls command in UNIX. (And to keep it simple, let's assume there are no command options or switches to worry about.) Clearly, one dimension of variation is the number of file names given. ls should handle not just one file name but also a list of many file names. And if no file names are given, ls is expected to have a completely different result. But what about each file name itself? ls will produce a different result, depending on whether the name identifies a simple file or a directory. So, the type of the file identified by each file name is an additional dimension of variation. But that's not all! Some file names could identify actual files, but others could be bogus names for files that don't exist, and this difference has a big effect of what ls is expected to do. So, here's another dimension of variation that has nothing to do with the file names themselves but instead concerns the state of the environment in which ls runs.
You can see that modeling the input space demands careful thought about the SUT. That's a job that no tool can do for you. But Tcases gives you a way to capture that knowledge and to translate it into effective test cases.
An Example: The find Command
To understand input modeling with Tcases, it helps to see an example in action. In this guide, we're going to explain how Tcases works by showing how we can use it to test a hypothetical find command. The complete input definition for find is included with this guide — you can see it here.
Take a look at the find specification below. What test cases would you use to test it?
Usage: find pattern file
Locates one or more instances of a given pattern in a text file.
All lines in the file that contain the pattern are written to standard output. A line containing the pattern is written only once, regardless of the number of times the pattern occurs in it.
The pattern is any sequence of characters whose length does not exceed the maximum length of a line in the file. To include a blank in the pattern, the entire pattern must be enclosed in quotes ("). To include a quotation mark in the pattern, two quotes in a row ("") must be used.
Defining System Functions
A system input definition describes a specific system-under-test, so the root element of the document looks like this:
<!-- All input definitions go here -->
</System>
In general, the SUT has one or more operations or "functions" to be tested. Accordingly, the System element contains a Function element for each of them.
<Function name="${myFunction-1}">
<!-- All input definitions for ${myFunction-1} go here -->
</Function>
<Function name="${myFunction-2}">
<!-- All input definitions for ${myFunction-2} go here -->
</Function>
...
</System>
Obviously, what constitutes a "system" or a "function" depends entirely on what you're testing. If your "system" is a Java class, then your "functions" might be its methods. If your "system" is an application, then your "functions" might be use cases. If your "system" is a Web site, then your "functions" might be pages. In any case, the process of input modeling is exactly the same.
For our example, we'll build an input definition for a system named "Examples" which has only one function named "find".
<Function name="find">
...
</Function>
</System>
Defining Input Variables
For each function to be tested, you need to define all of the dimensions of variation in its input space. For simplicity, Tcases refers to each such dimension as a "variable" and each basic variable is represented by a Var element. In addition, Tcases organizes input variables by type, using an Input element.
The find command has two different types of input variables. There are direct input arguments, such as the file name, which have input type arg. There are also other factors, such as the state of the file, which act as indirect "environmental" input variables and are given input type env. (More details about these are shown in a later section.)
<Function name="find">
<Input type="arg">
<!-- arg: Direct input arguments (the default) -->
<Var name="fileName">
...
</Var>
...
</Input>
<Input type="env">
<!-- env: Environment state variables -->
...
</Input>
...
</Function>
</System>
Actually, the type attribute of the Input element is just a tag that can be any value you want. And it is optional — if omitted, the default is arg. This grouping of inputs by type is available if you find it helpful. You can even define multiple Input elements with the same type if you want to. There is no limit to the number of different Input types that you can define.
Defining Input Values
For Tcases to create a test case, it must choose values for all of the input variables. How can it do that? Because we describe all of the possible values for each input variable using one or more Value elements.
By default, a Value element defines a valid value, one that the function-under-test is expected to accept. But we can use the optional failure attribute to identify an value that is invalid and expected to cause the function to produce some kind of failure response. Tcases uses these input values to generate two types of test cases — "success" cases, which use only valid values for all variables, and "failure" cases, which use a failure value for exactly one variable.
For example, we can define two possible values for the fileName argument to find.
<Input type="arg">
<Var name="fileName">
<!-- The required file name is defined -->
<Value name="defined"/>
<!-- The required file name is missing -- an error -->
<Value name="missing" failure="true"/>
...
</Input>
...
</Function>
That's it? Your only choices for the file name are "missing" or not? Good question! What's happening here is a very important part of input space modeling. It would be silly to list every possible file name as a Value here. Why? Because it just doesn't matter. At least for this particular function, the letters and format of the file name have no bearing on the behavior of the function. Instead, what's needed is a model of the value domain for this variable that characterizes the types of values that are significant to the test. This is a well-known test design technique known as equivalence class partitioning. You use each Value element to identify a class of values. By definition, all specific values in this class are test-equivalent. We don't need to test them all — any one of them will do.
In the case of the fileName variable, we've decided that the significance of file name itself is whether it is present or not, and we've chosen to identify those two variations as "defined" and "missing". But the name you use to identify each Value class is entirely up to you — it is part of the input model you design to describe your tests and it appears in the test case definitions that Tcases generates, to guide your test implementation.
Defining Variable Sets
It's common to find that a single logical input actually has lots of different characteristics, each of which creates a different "dimension of variation" in the input space. For example, consider the file that is searched by the find command. Does it even exist? Maybe yes, maybe no — that's one dimension of variation that the tests must cover. And what about its contents? Of course, you'd like to test the case where the file contains lines that match the pattern, as well the case where there are no matches. So, that's another dimension of variation. The spec says that each matching line is printed exactly once, even when it contain multiple matches. Wouldn't you want to test a file that has lines with different numbers of matches? Well, there's yet another dimension of variation. One file — so many dimensions!
You can model this complex sort of input as a "variable set", using a VarSet element. With a VarSet, you can describe a single logical input as a set of multiple Var definitions. A VarSet can even contain another VarSet, creating a hierarchy of logical inputs that can be extended to any number of levels.
For example, the single file input to the find command can modeled by the following variable set definition.
...
<Input type="env">
<VarSet name="file">
<!-- Does the file exist? -->
<Var name="exists">
<Value name="yes"/>
<Value name="no" failure="true"/>
</Var>
<!-- Does the file contain... -->
<VarSet name="contents">
<!-- ... any lines longer that the pattern? -->
<Var name="linesLongerThanPattern">
<Value name="one"/>
<Value name="many"/>
<Value name="none" failure="true"/>
</Var>
<!-- ... any matching lines? -->
<Var name="patterns">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
<!-- ... multiple matches in a line? -->
<Var name="patternsInLine">
<Value name="one"/>
<Value name="many"/>
</Var>
</VarSet>
</VarSet>
</Input>
...
</Function>
Isn't this hierarchy really just the same as four Var elements, something like the following?
...
<Var name="file.contents.linesLongerThanPattern">
...
<Var name="file.contents.patterns">
...
<Var name="file.contents.patternsInLine">
...
Yes, and when generating test cases, that's essentially how Tcases handles it. But defining a complex input as a VarSet makes the input model simpler to create, read, and maintain. Also, it allows you to apply constraints to an entire tree of variables at once, at you'll see in the next section.
Defining Constraints: Properties and Conditions
We've seen how to define the value choices for all of the input variables of each function-under-test, including complex input variables with multiple dimensions. That's enough for us to complete a system input definition for the find command that looks something like the following.
<Input type="arg">
<VarSet name="pattern">
<Var name="size">
<Value name="empty"/>
<Value name="singleChar"/>
<Value name="manyChars"/>
</Var>
<Var name="quoted">
<Value name="yes"/>
<Value name="no"/>
<Value name="unterminated" failure="true"/>
</Var>
<Var name="blanks">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
<Var name="embeddedQuotes">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
</VarSet>
<Var name="fileName">
<Value name="defined"/>
<Value name="missing" failure="true"/>
</Var>
</Input>
<Input type="env">
<VarSet name="file">
<Var name="exists">
<Value name="yes"/>
<Value name="no" failure="true"/>
</Var>
<VarSet name="contents">
<Var name="linesLongerThanPattern">
<Value name="one"/>
<Value name="many"/>
<Value name="none" failure="true"/>
</Var>
<Var name="patterns">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
<Var name="patternsInLine">
<Value name="one"/>
<Value name="many"/>
</Var>
</VarSet>
</VarSet>
</Input>
</Function>
When we run Tcases with this input document, we'll get a list of test case definitions like this:
<Function name="find">
<TestCase id="0">
<Input type="arg">
<Var name="pattern.size" value="empty"/>
<Var name="pattern.quoted" value="yes"/>
<Var name="pattern.blanks" value="none"/>
<Var name="pattern.embeddedQuotes" value="none"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="yes"/>
<Var name="file.contents.linesLongerThanPattern" value="one"/>
<Var name="file.contents.patterns" value="none"/>
<Var name="file.contents.patternsInLine" value="one"/>
</Input>
</TestCase>
<TestCase id="1">
<Input type="arg">
<Var name="pattern.size" value="singleChar"/>
<Var name="pattern.quoted" value="no"/>
<Var name="pattern.blanks" value="one"/>
<Var name="pattern.embeddedQuotes" value="one"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="yes"/>
<Var name="file.contents.linesLongerThanPattern" value="many"/>
<Var name="file.contents.patterns" value="one"/>
<Var name="file.contents.patternsInLine" value="many"/>
</Input>
</TestCase>
...
</Function>
</TestCases>
But wait up a second — something doesn't look right here. Take a closer look at test case 0 below. It's telling us to try a test case using a file that contains no instances of the test pattern. Oh, and at the same time, the file should contain a line that has one match for the test pattern. That seems sort of ... impossible.
<Input type="arg">
<Var name="pattern.size" value="empty"/>
<Var name="pattern.quoted" value="yes"/>
<Var name="pattern.blanks" value="none"/>
<Var name="pattern.embeddedQuotes" value="none"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="yes"/>
<Var name="file.contents.linesLongerThanPattern" value="one"/>
<Var name="file.contents.patterns" value="none"/>
<Var name="file.contents.patternsInLine" value="one"/>
</Input>
</TestCase>
And look at test case 1 below. It looks equally problematic. For this test case, the pattern should be a single character. And the pattern should contain one blank. And the pattern should contain one embedded quote character! No way!
<Input type="arg">
<Var name="pattern.size" value="singleChar"/>
<Var name="pattern.quoted" value="no"/>
<Var name="pattern.blanks" value="one"/>
<Var name="pattern.embeddedQuotes" value="one"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="yes"/>
<Var name="file.contents.linesLongerThanPattern" value="many"/>
<Var name="file.contents.patterns" value="one"/>
<Var name="file.contents.patternsInLine" value="many"/>
</Input>
</TestCase>
What's happening here? Clearly, some of the "dimensions of variation" described by these Var definitions are not entirely independent of each other. Instead, there are relationships among these variables that constrain which combinations of values are feasible. We need a way to define those relationships so that infeasible combinations can be excluded from our test cases.
With Tcases, you can do that using properties and conditions. The following sections explain how, including some tips about how to avoid certain problems that constraints can introduce.
Value properties
A Value definition can declare a property list that specifies one or more "properties" for this value. For example:
<Var name="size">
<Value name="empty" property="empty"/>
<Value name="singleChar" property="singleChar"/>
<Value name="manyChars"/>
</Var>
<Var name="quoted">
<Value name="yes" property="quoted"/>
<Value name="no"/>
<Value name="unterminated" failure="true"/>
</Var>
<Var name="blanks">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
<Var name="embeddedQuotes">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
</VarSet>
A property list is a comma-separated list of identifiers, each of which defines a "property" for this value. A property is just a name that you invent for yourself to identify an important characteristic of this value. The concept is that when this value is included in a test case, it contributes all of its properties — these now become properties of the test case itself. That makes it possible for us to later define "conditions" on the properties that a test case must (or must not!) have for certain values to be included.
For example, the definition above for the pattern.size variable says that when we choose the value empty for a test case, the test case acquires a property named empty. But if we choose the value singleChar, the test case acquires a different property named singleChar. And if we choose the value manyChars, no new properties are added to the test case. Note that the correspondence between these particular names of the values and properties is not exactly accidental — it helps us understand what these elements mean — but it has no special significance. We could have named any of them differently if we wanted to.
But note that all of this applies only to valid Value definitions, not to failure Value definitions that specify failure="true". Why? Because failure values are different!.
When a Value has a large set of properties, defining them in a long comma-separated list may look a little messy. In which case, you may find it tidier to define properties one at a time using the Property element. For example, instead of this:
<Value name="V1" property="this,is,a,ridiculously,long,list,of,property,names"/>
...
</Var>
You could create an equivalent definition like this:
<Value name="V1">
<Property name="this"/>
<Property name="is"/>
<Property name="a"/>
<Property name="ridiculously"/>
<Property name="long"/>
<Property name="list"/>
<Property name="of"/>
<Property name="property"/>
<Property name="names"/>
</Value>
...
</Var>
Value conditions
We can define the conditions required for a Value to be included in a test case using the when and whenNot attributes. Each of these defines a comma-separated list of property identifiers. Adding a when list means "for this value to be included in a test case, the test case must have all of these properties". Similarly, a whenNot list means "for this value to be included in a test case, the test case must not have any of these properties".
For example, consider the conditions we can define for the various characteristics of the pattern input.
<Var name="size">
<Value name="empty" property="empty"/>
<Value name="singleChar" property="singleChar"/>
<Value name="manyChars"/>
</Var>
<Var name="quoted">
<Value name="yes" property="quoted"/>
<Value name="no" whenNot="empty"/>
<Value name="unterminated" failure="true"/>
</Var>
<Var name="blanks">
<Value name="none"/>
<Value name="one" when="quoted, singleChar"/>
<Value name="many" when="quoted" whenNot="singleChar"/>
</Var>
<Var name="embeddedQuotes">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
</VarSet>
This defines a constraint on the pattern.quoted variable. We want to have a test case in which the value for this variable is no, i.e. the pattern string is not quoted. But in this case, the pattern.size cannot be empty. Because that combination doesn't make sense, we want to exclude it from the test cases generated by Tcases.
Similarly, we define a constraint on the pattern.blanks variable, which specifies how many blanks should be in the pattern string. We want a test case in which the value is many. But in such a test case, the pattern must be quoted (otherwise, a blank is not possible) and it must not be a single character (which would contradict the requirement for multiple blanks).
This also defines another constraint on any test case in which the value of pattern.blanks is one. In such a test case, of course, the pattern must be quoted. And we've declared also that the pattern size must be a single character. But why? That doesn't seem strictly necessary. What's wrong with a pattern that has multiple characters and only one blank? Well, nothing — that's a perfectly good combination. But isn't a pattern that is exactly one blank character a more interesting test case? Isn't that a case that could expose a certain kind of defect in the pattern matching logic? And isn't the case of many-chars-one-blank unlikely to expose any defects not visible in the many-chars-many-blanks case? This demonstrates another way for a smart tester to use properties and conditions: to steer toward test cases with more potent combinations and away from combinations that add little defect-fighting power.
It's important to note that there are no conditions attached to choosing a value of none for pattern.blanks. A test case can use this value in combination with any others. And that's a good thing. We want to model the reality of the input space for the function, without eliminating any test cases that are actually feasible. Otherwise, our tests will have a blind spot that could allow defects to slip by undetected. Rule of thumb: Use conditions sparingly and only when necessary to avoid infeasible or unproductive test cases.
Failure values are different!
Different? Yes, because failure Value definitions — i.e. those that specify failure="true" — cannot define properties.
If you think about it, you can see that there is a fundamental reason why this is so. Suppose you declare that some value=V defines a property=P. Why would you do that? There really is only one reason: so that some other value=O can require combination with V (or, to be precise, with any value that defines P). But if V declares failure="true", that doesn't make sense. If the other value O is valid, it can't demand combination with a failure value — otherwise, O could never appear in a success case. And if O is a failure value itself, it can't demand combination with a different failure value — at most one failure value can appear in a failure case.
But note that a failure Value can define a condition. In other words, it can demand combination with specific values from other variables. By working from this direction, you can control the other values used in a failure case.
Variable conditions
You may find that, under certain conditions, an input variable becomes irrelevant. It doesn't matter which value you choose — none of them make a difference in function behavior. It's easy to model this situation — just define a condition on the Var definition itself.
For example, when we're testing the find command, we want to try all of the values defined for every dimension of the pattern variable set. But, in the case when the pattern string is empty, the question of how many blanks it contains is pointless. In this case, the pattern.blanks variable is irrelevant. Similarly, when we test a pattern string that is only one character, the pattern.embeddedQuotes variable is meaningless. We can capture these facts about the input space by adding Var constraints, as shown below.
<Var name="size">
<Value name="empty" property="empty"/>
<Value name="singleChar" property="singleChar"/>
<Value name="manyChars"/>
</Var>
<Var name="quoted">
<Value name="yes" property="quoted"/>
<Value name="no" whenNot="empty"/>
<Value name="unterminated" failure="true"/>
</Var>
<Var name="blanks" whenNot="empty">
<Value name="none"/>
<Value name="one" when="quoted, singleChar"/>
<Value name="many" when="quoted" whenNot="singleChar"/>
</Var>
<Var name="embeddedQuotes" whenNot="empty, singleChar">
<Value name="none"/>
<Value name="one"/>
<Value name="many"/>
</Var>
</VarSet>
You can define variable constraints at any level of a variable set hierarchy. For example, you can see in the example above that a constraint is defined for the entire pattern variable set. This constraint models the fact that the pattern is irrelevant when the file specified to search doesn't even exist.
How does a variable constraint affect the test cases generated by Tcases? In a test case where a variable is irrelevant, it is not given a value but instead is designated as NA, meaning "not applicable". For example, test case 0 below shows how testing an empty pattern causes pattern.blanks and pattern.embeddedQuotes to be irrelevant. Similarly, test case 8 shows how testing with a non-existent file makes nearly every other variable irrelevant.
<Input type="arg">
<Var name="pattern.size" value="empty"/>
<Var name="pattern.quoted" value="yes"/>
<Var name="pattern.blanks" NA="true"/>
<Var name="pattern.embeddedQuotes" NA="true"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="yes"/>
<Var name="file.contents.linesLongerThanPattern" value="one"/>
<Var name="file.contents.patterns" NA="true"/>
<Var name="file.contents.patternsInLine" NA="true"/>
</Input>
</TestCase>
...
<TestCase id="8" failure="true">
<Input type="arg">
<Var name="pattern.size" NA="true"/>
<Var name="pattern.quoted" NA="true"/>
<Var name="pattern.blanks" NA="true"/>
<Var name="pattern.embeddedQuotes" NA="true"/>
<Var name="fileName" value="defined"/>
</Input>
<Input type="env">
<Var name="file.exists" value="no" failure="true"/>
<Var name="file.contents.linesLongerThanPattern" NA="true"/>
<Var name="file.contents.patterns" NA="true"/>
<Var name="file.contents.patternsInLine" NA="true"/>
</Input>
</TestCase>
Complex conditions
The when and whenNot attributes are sufficient to express the most common constraints on Var and Value definitions. But what if the condition you need is more complicated? For example, what about a Value that can be included only if a test case has either property X or property Y? For such situations, you can define conditions using a When element. A When element can appear as a subelement of any definition that allows a condition: Value, Var, or VarSet.
For example, the condition for a test case to include a pattern with many blank characters can be expressed with a When element like this:
...
<Var name="blanks" whenNot="empty">
<Value name="none"/>
<Value name="one" when="quoted, singleChar"/>
<Value name="many">
<When>
<!-- All of the condition below are true... -->
<AllOf>
<!-- ... all of the following properties are present... -->
<AllOf property="quoted"/>
<!-- ... and none of the following properties are present. -->
<Not property="singleChar"/>
</AllOf>
</When>
</Value>
</Var>
...
</VarSet>
A When element contains a single subelement that defines a boolean expression. The basic boolean expressions are:
- AllOf: a logical "AND" expression
- AnyOf: a logical "OR" expression
- Not: a logical negation expression
All of these basic boolean expressions have a similar structure. They can have an optional property list, which specifies the properties that are subject to this expression. Also, they can contain any number of additional boolean expressions as subelements. For example:
<Not property="A">
<AnyOf property="B">
<AllOf property="C, D"/>
</AnyOf>
</Not>
</When>
This When expression is equivalent to the following boolean expression in Java.
The when and whenNot attributes are shorthand for the equivalent When expression, and these alternatives are mutually exclusive. If you use either of these attributes, you can't specify a When element in the same definition and vice versa.
Cardinality conditions
The basic boolean conditions are concerned only with the presence (or absence) of certain properties in a test case. But, of course, a test case can accumulate multiple instances of a property, if two or more of the values used in the test case contribute the same property. And in some situations, the number of occurrences of a property is a significant constraint on the input space. You can model these situations using cardinality conditions, which check if the number of property occurrences is greater than, less than, or equal to a specific value.
For example, consider the case of an ice cream shop that sells different types of ice cream cones. These yummy products come only in specific combinations, and the price depends on the combination of scoops and toppings added. But how to test that? The input model for these cones might look like the one below. (You can find the full example here.)
<Function name="Cones">
<Input>
<Var name="Cone">
<Value name="Empty" failure="true"> ... </Value>
<Value name="Plain"> ... </Value>
<Value name="Plenty"> ... </Value>
<Value name="Grande"> ... </Value>
<Value name="Too-Much" failure="true"> ... </Value>
</Var>
<VarSet name="Flavors">
<Var name="Vanilla"> ... </Var>
<Var name="Chocolate"> ... </Var>
<Var name="Strawberry"> ... </Var>
<Var name="Pistachio"> ... </Var>
<Var name="Lemon"> ... </Var>
<Var name="Coffee"> ... </Var>
</VarSet>
<VarSet name="Toppings">
<Var name="Sprinkles"> ... </Var>
<Var name="Pecans"> ... </Var>
<Var name="Oreos"> ... </Var>
<Var name="Cherries"> ... </Var>
<Var name="MMs"> ... </Var>
<Var name="Peppermint"> ... </Var>
</VarSet>
</Input>
</Function>
</System>
To build a cone, you can add a scoop of any flavor and any of the given toppings. To keep track, each of these choices contributes either a scoop or a topping property to our cone test cases.
<Function name="Cones">
<Input>
...
<VarSet name="Flavors">
<Var name="Vanilla">
<Value name="Yes" property="scoop"/>
<Value name="No"/>
</Var>
...
<Var name="Coffee">
<Value name="Yes" property="scoop"/>
<Value name="No"/>
</Var>
</VarSet>
<VarSet name="Toppings" when="scoop">
<Var name="Sprinkles">
<Value name="Yes" property="topping"/>
<Value name="No"/>
</Var>
...
<Var name="Peppermint">
<Value name="Yes" property="topping"/>
<Value name="No"/>
</Var>
</VarSet>
</Input>
</Function>
</System>
Then we can define specific cone products based on the number of scoops and toppings, using cardinality conditions like LessThan, Equals, and Between.
<Function name="Cones">
<Input>
<Var name="Cone">
<Value name="Empty" failure="true">
<When>
<LessThan property="scoop" max="1"/>
</When>
</Value>
<Value name="Plain">
<When>
<AllOf>
<Equals property="scoop" count="1"/>
<NotMoreThan property="topping" max="1"/>
</AllOf>
</When>
</Value>
<Value name="Plenty">
<When>
<AllOf>
<Between property="scoop" min="1" max="2"/>
<NotMoreThan property="topping" max="2"/>
</AllOf>
</When>
</Value>
<Value name="Grande">
<When>
<AllOf>
<Between property="scoop" exclusiveMin="0" exclusiveMax="4"/>
<Between property="topping" min="1" max="3"/>
</AllOf>
</When>
</Value>
<Value name="Too-Much" failure="true">
<When>
<AnyOf>
<MoreThan property="scoop" min="3"/>
<NotLessThan property="topping" min="4"/>
</AnyOf>
</When>
</Value>
</Var>
...
</Input>
</Function>
</System>
Here's a complete list of all the cardinality conditions you can use.
- LessThan: Satisfied when the given property occurs less than the given max times.
- NotLessThan: Satisfied when the given property occurs greater than or equal to the given min times.
- MoreThan: Satisfied when the given property occurs more than the given min times.
- NotMoreThan: Satisfied when the given property occurs less than or equal to the given max times.
- Between: Satisfied when occurrences of the given property are both greater than or equal to the given min and less than or equal to the given max. If you want to specify a strictly greater/less than relationship, specify an exclusiveMin or exclusiveMax attribute instead.
- Equals: Satisfied when the given property occurs exactly the given count times.
But be careful!
With the constraints defined by properties and conditions comes great power. Use it carefully! It's possible to define constraints that make it very difficult or even impossible for Tcases to generate the test cases you want. If it looks to you like Tcases is frozen, that's probably what's going on. Tcases is not frozen — it's busy with a very long and perhaps fruitless search for a combination of values that will satisfy your constraints.
The following sections describe some of the situations to watch out for.
Infeasible combinations
Tcases always generates test cases that include specific combinations of values, based on the coverage level you've specified. But what if you've defined constraints that make some intended value combination impossible? If so, we say that this combination is "infeasible". For combinations of 2 or more variables (2-tuples, 3-tuples, etc.), this may be expected, so Tcases will simply log a warning and keep going. For "combinations" of a single variable (the default coverage level), this is an error, and you must fix the offending constraints before Tcases can continue.
- To help find the bad constraint that's giving you grief, try changing the logging level to DEBUG or TRACE.
-
Are you using higher coverage levels (2-tuples, 3-tuples, etc.)?
If so, try running a quick check using only the default coverage. An easy way to do that is
to run Tcases like this:
tcases < <myInputModelFile> . If there is an infeasible value, this check can sometimes show you the error.
Usually, Tcases can quickly report when combinations are infeasible. But in some cases, Tcases can find the problem only after trying and eliminating all possibilities. If it looks to you like Tcases is frozen, that's probably what's going on. Tcases is not frozen — it's busy with a long, exhaustive, and ultimately fruitless search.
To avoid such problems, it helps to remember this simple rule: every "success" test case must define a valid value for all variables. For any individual variable V, no matter which values are chosen for the other variables in a success test case, there must be at least one valid value of V that is compatible with them.
For example, the following variable definitions are infeasible. There is no way to complete a success test case containing Shape=Square because there is no valid value for Color that is compatible with it.
<Value name="Square" property="quadrilateral"/>
<Value name="Circle"/>
</Var>
<Var name="Color">
<Value name="Red" whenNot="quadrilateral"/>
<Value name="Green" whenNot="quadrilateral"/>
<Value name="Blue" whenNot="quadrilateral"/>
<Value name="Chartreuse" failure="true"/>
</Var>
The only exception is for conditions in which a variable is defined to be entirely irrelevant. For example, the following definitions are OK, because they explicitly declare that Color is incompatible with Shape=Square.
<Value name="Square" property="quadrilateral"/>
<Value name="Circle"/>
</Var>
<Var name="Color" whenNot="quadrilateral">
<Value name="Red"/>
<Value name="Green"/>
<Value name="Blue"/>
<Value name="Chartreuse" failure="true"/>
</Var>
Large AnyOf conditions
You can use an AnyOf condition to define a logical "OR" expression. But beware an AnyOf that contains a large number of subexpressions. When Tcases is looking for value combinations to satisfy such a condition, it must evaluate a large number of possibilities. As the number of subexpressions increases, the number of possibilities increases exponentially! This can quickly get out of hand, even when a satisfying combination exists. And things go from bad to worse if this AnyOf makes an intended test case infeasible. If it looks to you like Tcases is slow or frozen, that may be what's going on.
If you face this situation, you should try to find a way simplify the large AnyOf condition. For example, you may be able to eliminate subexpressions by assigning special properties that produce an equivalent result.
Defining Input Coverage
Tcases generates test case definitions by creating combinations of values for all input variables. But how does it come up with these combinations? And why these particular combinations and not others? And just how good are these test cases? Can you rely on them to test your system thoroughly?
Good questions. And here's the basic answer: Tcases generates the minimum number of test cases needed to meet the coverage requirements that you specify. But to understand what that means, you need to understand how Tcases measures coverage.
Combinatorial Testing Basics
Tcases is concerned with input space coverage — how many of the feasible combinations of input values are tested. To measure input space coverage, Tcases is guided by concepts from the field of combinatorial testing. As testers, we're looking for combinations of input values that will trigger a failure, thus exposing a defect in the SUT. But, in general, we can't afford the effort to test every combination. We have to settle for some subset. But how?
Suppose we tried the following approach. For the first test case, just pick a valid value for every input variable. Then, for the next test case, pick a different valid value for every variable. Continue this until we've used every valid value of every variable at least once. Of course, as we do this, we'll skip over any infeasible combinations that don't satisfy our constraints. The result will be a fairly small number of test cases. In fact, assuming there are no constraints on input values, the number of "success" cases created by this procedure will be S, where S is the maximum number of valid values defined for any one variable. For the failure cases, we can do something similar by creating a new test case for each invalid value, substituting it into an otherwise-valid combination of other values. That gives us F more test cases, where F is the total number of invalid values for all variables. So that's S+F tests cases, a pretty small test suite that ought to be quite doable. But what is the coverage? Well, we've guaranteed that every value of every variable is used at least once. That is what is known as "1-way coverage" or "1-tuple coverage" — all "combinations" of 1 variable. (This is also known as "each choice coverage".)
But is that good enough? Experience (and research) teaches us that many failures are triggered by the interaction of two or more variables. So maybe we should aim for a higher level of input coverage. We could iterate over every pair of input variables and consider every combination of their values. For example, the pattern.size variable has 3 valid values and the pattern.quoted variable has 2 valid values. That makes 6 combinations for this pair of variables (ignoring constraints). For each pair, create a test case and fill it out with values for all of the other variables. In the end, we'll have a test suite that uses every such pair at least once — that's "2-way coverage" or "2-tuple coverage" (also known as "pairwise coverage"). This is a much stronger test suite — more likely to find many defects — but it's also a larger number of test cases.
We can extend the same approach to even higher levels of combinatorial coverage — 3-way coverage, 4-way coverage, etc. With each higher level, our tests become more powerful. But the price is that the number of test cases increases rapidly with each additional level. At some point, the gain is not worth the pain. In fact, research indicates that very few failures are caused by the interaction of 4 or more variables, and failures that require an interaction of 6 or more variables are virtually unknown. Most failures appear to be triggered by 1- or 2-way interactions. But that doesn't necessarily mean you should stop at 2-way coverage. Every system has its own unique risks. Also, not all variables interact equally — you may have some sets of variables that need a higher level of coverage than the rest.
Note that the number of test cases required to meet a specific level of coverage depends on many factors. Naturally, the number of test cases needed for N-way coverage increases for larger values of N. Also, variables that have a large number of values create more combinations to be covered, which may demand more test cases. Also, when there are constraints among input values, the number of test cases tends to increase. For example, a variable condition means that some test cases must use NA="true" for that variable, which means that additional test cases are needed to cover the real values.
Failure Cases Are Different!
Notice that when we talk about the various levels of N-way variable combinations, we are careful to apply these combinations only to valid values of these variables. Why? Because failures cases are different!
Clearly, for every variable, each invalid value (i.e. with failure="true") deserves its own test case. A "failure" case like this should have an invalid value for exactly one variable and valid values for all of the other variables. That's the only sure way to verify that an expected failure can be attributed to solely to this invalid value. Consequently, it should be understood that the number of failure cases generated by Tcases will always be equal to the number of invalid values, regardless of the combinatorial coverage level used.
Of course, for any given level of N-way valid combinations, the set of failure cases will nearly always include some of those combinations. But that doesn't count! For true N-tuple coverage, a test set must include every valid combination in at least one "success" case. Again, the reason for this should be clear. That's the only sure way to verify the expectation that this combination leads to a valid result.
Default Coverage
For the record, the default for Tcases is 1-tuple coverage. In other words, unless you specify otherwise, Tcases will translate your system input definition into a minimal set of test case definitions that uses every value of every variable — every "1-tuple" — at least once, while satisfying all constraints.
Is that good enough? Maybe. If you've built your system input definition carefully, you're likely to find that a 1-tuple coverage test suite also achieves upward of 75% basic block (line) coverage of the SUT. In fact, using Tcases in tandem with a structural coverage tool like Emma or Cobertura can be very effective. Tip: Use Tcases to create a 1-tuple coverage test suite, then measure structural coverage to identify any gaps in the system input definition. You can repeat this process to quickly reach a small but powerful set of test cases.
But to get the tests you need faster, you may need to selectively apply 2-tuple coverage or higher. The next section explains how.
Defining Higher Coverage
For higher levels of coverage, you need to create a generator definition that specifies your coverage requirements in detail. A generator definition, which is another document that Tcases applies to your system input definition, defines a set of "generators".
<TupleGenerator function="${myFunction-1}">
<!-- Coverage requirements for ${myFunction-1} go here -->
</TupleGenerator>
<TupleGenerator function="${myFunction-2}">
<!-- Coverage requirements for ${myFunction-2} go here -->
</TupleGenerator>
...
</Generators>
The simplest possible generator definition looks like this:
<!--For all functions (the default), generate 1-tuple coverage (the default)-->
<TupleGenerator/>
</Generators>
To require 2-tuple coverage for all variables of all functions, you would create a generator definition like this:
<!-- Generate 2-tuple coverage for all functions -->
<TupleGenerator tuples="2"/>
</Generators>
To require 3-tuple coverage only for the function named F, while generating 2-tuple coverage for all other functions, you would create a generator definition like the one below. Notice that you can explicitly identify "all functions" using the special function name *. Or you can just leave the function attribute undefined, which has the same effect.
<!-- By default, generate 2-tuple coverage for all functions -->
<TupleGenerator function="*" tuples="2"/>
<!-- But generate 3-tuple coverage for F -->
<TupleGenerator function="F" tuples="3"/>
</Generators>
Defining Multiple Levels Of Coverage
When you look carefully at the functions of your system-under-test, you may well find that some of them call for more intense testing than others. That's what a generator definition allows you to do. In fact, when you look carefully at a single function, you may be more concerned about the interactions between certain specific variables. You may even want to test every possible permutation for a small subset of key variables. Is it possible to get high coverage in a few areas and basic coverage everywhere else? Why, yes, you can. This section explains how.
You've already seen how you can specify different levels of coverage for different functions. For finer control, you can use one or more Combine elements. A Combine element defines the level of coverage generated for a specific subset of Var definitions. You specify which variables to combine using a variable "path pattern". For example:
<!-- With 1-tuple coverage (the default) for un-Combine-ed variables... -->
<TupleGenerator function="find">
<!-- ...Generate 2-tuple coverage for... -->
<Combine tuples="2">
<!-- ... all Vars in the "pattern" variable set -->
<Include var="pattern.*"/>
</Combine>
</TupleGenerator>
</Generators>
A variable path pattern describes a path to a specific Var, possibly nested within a VarSet hierarchy. Wildcards allow you to match all immediate children (*) or all descendants (**) of a VarSet. Note that a pattern can contain at most one wildcard, which can appear only at the end of the path.
You can use a combination of Include and Exclude elements to concisely describe exactly which variables to combine. You can specify as many Include or Exclude elements as you need. For example:
<!-- With 1-tuple coverage (the default) for un-Combine-ed variables... -->
<TupleGenerator function="find">
<!-- ...Generate 2-tuple coverage for... -->
<Combine tuples="2">
<!-- ... all variables except for Vars in the "file" set -->
<Exclude var="file.**"/>
</Combine>
</TupleGenerator>
</Generators>
<!-- With 2-tuple coverage for un-Combine-ed variables... -->
<TupleGenerator function="find" tuples="2">
<!-- ...Generate 1-tuple coverage (the default) for... -->
<Combine>
<!-- ...all Vars in the "pattern" variable set... -->
<Include var="pattern.*"/>
<!-- ...except "embeddedQuotes" -->
<Exclude var="pattern.embeddedQuotes"/>
</Combine>
</TupleGenerator>
</Generators>
A Combine element that specifies the special value tuples="0" generates test cases that include all possible value permutations of the included variables. Obviously, this setting has the potential to create a huge number of test cases, so it should be used sparingly and only for small sets of variables. For example:
<!-- With 1-tuple coverage (the default) for un-Combine-ed variables... -->
<TupleGenerator function="find">
<!-- Include all permutations of the "pattern" variable set -->
<Combine tuples="0">
<Include var="pattern.*"/>
</Combine>
</TupleGenerator>
</Generators>
Each Combine element defines how to combine a specific set of variables. But what about the variables that are not included in any Combine? For these, Tcases automatically creates a default Combine group, using the default tuples defined for the TupleGenerator.
Managing A Tcases Project
Using Tcases to design a test suite means:
- Learning about the expected behavior of the SUT
- Creating an initial system input definition
- Generating, evaluating, and improving test case definitions
- Evaluating and improving coverage requirements
- Changing input definitions to handle new cases
You might finish all these tasks very quickly. Or this effort might extend over a significant period of time. Either way, that's a project. This section offers some tips to help you complete your Tcases project more effectively.
Managing Project Files
A Tcases project must deal with several closely-related files: a system input definition, zero or more generator definitions, and the test case definition document that is generated from them (possibly in multiple forms). The tcases command implements some conventions that make it easier to keep these files organized.
The tcases command allows you to refer to all of the files for a project named ${myProjectName} using the following conventions.
- ${myProjectName}-Input.xml: the system input definition file
- ${myProjectName}-Generators.xml: the generator definition file
- ${myProjectName}-Test.xml: the test case definition file
For example, here's a simple way to run Tcases.
This command performs the following actions.
- Reads the system input definition from ${myProjectName}-Input.xml
- Reads the generator definition from ${myProjectName}-Generators.xml, if it exists
- Writes test case definitions to ${myProjectName}-Test.xml
Of course, you can use various options for the tcases command to customize this default pattern. For details, see the TcasesCommand.Options class, or run tcases -help.
Reusing Previous Test Cases
You know the feeling. You've spent days figuring out a minimal set of test cases that covers all test requirements. Then the developer walks up with the great news: they've decided to add a new feature with some new parameters. And they've changed their minds about some things. You know that required parameter? Well, it's optional now — leaving it blank is no longer an error. Sometimes is seems they're doing this just to torture you. But, honestly, most of the time it's just the normal progression of a development project. After a few iterations, you've gained more knowledge that you need to apply to the system you're building. Or after a release or two, it's time to make the system do new tricks.
Either way, it's back to the ol' test drawing board. Or is it? You're not changing everything. Why can't you just tweak the test cases you already have? Funny you should ask. Because that's exactly what Tcases can do. In fact, it's the default way of working. Remember that simple tcases command line?
Here's what it really does:
- Reads the system input definition from ${myProjectName}-Input.xml
- Reads the generator definition from ${myProjectName}-Generators.xml, if it exists
- And reads previous test cases from ${myProjectName}-Test.xml, if it exists
- Then writes new test case definitions to ${myProjectName}-Test.xml which reuse as much of the previous test cases as possible, extending or modifying them as needed
You might prefer to ignore previous test cases and just create new ones from scratch. That's especially true in the early stages of your project while you're still working out the details of the system input definition. If so, you can use the -n option to always create new tests cases, ignoring any previous ones.
Mix It Up: Random Combinations
By default, Tcases creates combinations of input variables by marching through the system input definition top-to-bottom, picking things up in the order in which it finds them. You might try to exploit that natural order, although satisfying constraints can take things off a predictable sequence. That's why you really shouldn't care too much about which combinations Tcases comes up with. Even better? Ask Tcases to randomize its combination procedure.
You can define random combinations in your generator definition by using the seed attribute — see the example below. This integer value acts as the seed for a random number generator that controls the combination process. Alternatively, you can (re)define the seed value using command line options described in later sections. By specifying the seed explicitly, you ensure that exactly the same random combinations will be used every time you run Tcases with this generator definition.
<TupleGenerator function="find" seed="200712190644">
...
</TupleGenerator>
</Generators>
The results of random combination can be very interesting. First, you can end up with test cases that you might not have considered, even though they are perfectly valid and produce the same coverage. Sometimes that's just enough to expose a defect that might otherwise have been overlooked, simply because no one thought to try that case. This is an application of the principle of "gratuitous variety" to improve your tests. This also produces another benefit — sometimes an unusual combination can demonstrate a flaw in your test design. If a combination just doesn't make sense, then it's likely that a constraint is missing or incorrect.
Finally, random combinations can occasionally reduce the number of test cases needed to meet your coverage requirements. That's because some combinations may "consume" variable tuples more efficiently than other equally-valid combinations. Tcases does not attempt to spend the enormous effort needed to guarantee an optimally minimal set of test cases. It simply starts at the beginning and does its best to get quickly to the end. But a random walk through the combinations may lead Tcases to a more efficient path. If you're concerned about the size of your test suite, try the Tcases Reducer.
Reducing Test Cases: A Random Walk
A random walk through the combinations may lead Tcases to a smaller set of test cases. So you could try repeatedly altering your generator definition with a bunch of different seed values, searching for one that minimizes the size of the generated test definition file. Sounds tedious, huh? So, don't do that — use the Tcases Reducer instead.
Here how to do it, using the tcases-reducer command.
> cd docs/examples/xml
> tcases-reducer find-Input.xml
And the result? Now there is a find-Generators.xml file that looks something like this: a generator definition that uses a random seed for all functions.
<Generators>
<TupleGenerator function="*" seed="1909310132352748544" tuples="1">
</TupleGenerator>
</Generators>
But why this seed value? For a detailed view, look at the resulting tcases-reducer.log file (see example below). First, the Reducer generates test cases without using a random seed, producing 10 test cases. Then, the Reducer tries again, and it reduces the results to 9 test cases. Then, the Reducer tries several more time, each time using a different random seed. Finally, the Reducer cannot find a greater reduction, so it terminates.
INFO o.c.t.generator.TupleGenerator - FunctionInputDef[find]: generating test cases
...
INFO o.c.t.generator.TupleGenerator - FunctionInputDef[find]: completed 10 test cases
INFO o.c.t.generator.TupleGenerator - FunctionInputDef[find]: generating test cases
...
INFO o.c.t.generator.TupleGenerator - FunctionInputDef[find]: completed 9 test cases
INFO org.cornutum.tcases.Reducer - Round 1: after 2 samples, reached 9 test cases
...
INFO org.cornutum.tcases.Reducer - Round 2: after 10 samples, terminating
INFO org.cornutum.tcases.Reducer - Updating generator definition=find-Generators.xml
The Reducer handles all the work of searching for the best random seed, without overwriting any existing test definition files. Here's how it works. The reducing process operates as a sequence of "rounds". Each round consists of a series of test case generations called "samples". Each sample uses a new random seed to generate test cases for a specified function (or, by default, all functions) in an attempt to find a seed that produces the fewest test cases. If all samples in a round complete without reducing the current minimum test case count, the reducing process terminates. Otherwise, as soon as a new minimum is reached, a new round begins. The number of samples in each subsequent round is determined using a "resample factor". At the end of the reducing process, the generator definition file for the given system input definition is updated with the random seed value that produces the minimum test case count.
Even though the Reducer produces a random seed that minimizes test cases, you still have to consider if these test cases are satisfactory. You might wonder if a different seed might produce an equally small but more interesting set of test cases. If so, try using the -R option. This tells the Reducer to ignore any previous random seed in the generator definition and to search for a new seed value.
For details about all the options for the tcases-reducer command (and its Windows counterpart tcases-reducer.bat), see the Javadoc for the ReducerCommand.Options class. To get help at the command line, run tcases-reducer -help.
Avoiding Unneeded Combinations
Even when Tcases is generating test cases for the default 1-tuple coverage, it's typical to see some input values used many times. This is most likely for those Var elements that contain only a few Value definitions. Even after these values have been used, Tcases will continue to reuse them to fill out the remaining test cases needed to complete the test suite. In some situations, this can be a bit of a pain. Sometimes there is a Value that you need to test at least once, but for various reasons, including it multiple times adds complexity without really increasing the likelihood of finding new failures. In this case, you can use the once attribute as a hint to avoiding reusing a value more than once.
For example, the find command requires that the pattern must not exceed the maximum length of a line in the file. Even one line longer than the pattern would be enough to avoid this error condition. In fact, the principles of boundary value testing suggest that it's a good idea to have a test case that has exactly one line longer. Therefore:
...
<VarSet name="contents" when="fileExists">
<Var name="linesLongerThanPattern">
<Value name="one" property="matchable"/>
<Value name="many" property="matchable"/>
<Value name="none" failure="true"/>
</Var>
...
</VarSet>
</VarSet>
But this is a corner case that doesn't bear repeating. It's a chore to create a test file that meets this special condition, and it's complicated to stretch such a file to meet additional conditions. Moreover, it's unlikely that this special condition will have higher-order interactions with other variable combinations. So let's add once="true" to request Tcases to include this value in only one test case.
...
<VarSet name="contents" when="fileExists">
<Var name="linesLongerThanPattern">
<Value name="one" property="matchable" once="true"/>
<Value name="many" property="matchable"/>
<Value name="none" failure="true"/>
</Var>
...
</VarSet>
</VarSet>
Nice! But keep in mind that the once hint may not always be respected. Even when once="true", a Value may be used more than once if it is needed to satisfy a constraint in remaining test cases.
The once hint is actually a shortcut that applies only to a 1-tuple for a single variable Value. If the generator definition includes this variable in higher-order tuples, once has no effect. But the same situation can occur with higher-order combinations, too. For example, although you may want pairwise coverage for a certain set of variables, one or more of these 2-tuples may be special cases that should be used at most once. To define such exceptions you can add one or more Once elements to your generator definition. For example:
<!-- Generate 1-tuple coverage for all variables... -->
<TupleGenerator function="find">
<Combine tuples="2">
<!-- ... but 2-tuple coverage for Vars in the "pattern" variable set -->
<Include var="pattern.*"/>
<!-- ... using the following 2-tuple at most once -->
<Once>
<Var name="pattern.size" value="manyChars"/>
<Var name="pattern.quoted" value="yes"/>
</Once>
</Combine>
</TupleGenerator>
</Generators>
Simple Generator Definitions
Tcases provides some options to make it easier to create and update a simple generator definition document.
Defining A Random Seed
To define a random combination seed, use the -r option. For example, the following command generates test cases with a default TupleGenerator that uses the specified seed value.
If you already have a ${myProjectName}-Generators.xml file, this command will update the file by adding or changing the default seed value, as shown below. If no ${myProjectName}-Generators.xml file exists, it will create one.
<TupleGenerator seed="299293214"/>
</Generators>
If you'd like to randomize combinations but you're not particular about the seed value, use the -R option, and Tcases will choose a random seed value for you. This option can be handy when you want to see if a different seed value might produce more interesting test case combinations.
Defining The Default Coverage Level
To define the default coverage level for all functions, use the -c option. For example, the following command generates test cases with a default TupleGenerator that uses the specified coverage level.
If you already have a ${myProjectName}-Generators.xml file, this command will update the file by adding or changing the default tuples value, as shown below. If no ${myProjectName}-Generators.xml file exists, it will create one.
<TupleGenerator tuples="2"/>
</Generators>
Troubleshooting FAQs
- Help! Tcases keeps running and never finishes!
You have probably over-constrained your input model, making it difficult or impossible to generate test cases that satisfy all of the constraints. But that won't stop Tcases from trying until it has eliminated all possible combinations. Which, in some cases, can take a very long time. Tcases is not frozen — it's busy with a long, exhaustive, and possibly fruitless search.
To fix this, check your condition and property settings until you find the problem. You can find more details about this situation here. - How can I see more details about what Tcases is doing?
Tcases uses the Logback system for producing a log of its actions. By default, log messages are written to a file named tcases.log in the current working directory, although you can redirect them to standard output by using the
-l stdout option.
The default logging level is INFO, which shows only basic progress and error information. To see more details, change the logging level to DEBUG using the -L option. To see even more details, change the logging level to TRACE.
Transforming Test Cases
The test case definitions that Tcases produces are not directly executable. Their purpose is to specify and guide the construction of actual tests. But because test case definitions can appear in a well-defined XML document, it's not hard to transform them into a more concrete form. This section describes the options Tcases offers for output transformations.
Creating An HTML Report
The XML form for test case definitions is pretty simple. But let's face it — reading XML is not always a lot of fun. It's not necessarily what you'd want to hand someone for guidance during manual testing. So how about looking at the same information in a nice Web page on your browser? To do that, just add the -H option to your tcases command, and Tcases will automatically write test case definitions in the form of an HTML file.
Here's a simple example. Try out these commands:
> cd docs/examples/xml
> tcases -H find
This runs Tcases on the input definitions in find-Input.xml and produces a file named find-Test.htm. Open this file with your browser and you'll see something like the simple HTML report below. This report allows you to browse through all of the test cases and look at each one of them in detail. You'll see all of the input values needed for the selected test case (omitting any input variables that are irrelevant for this test case).
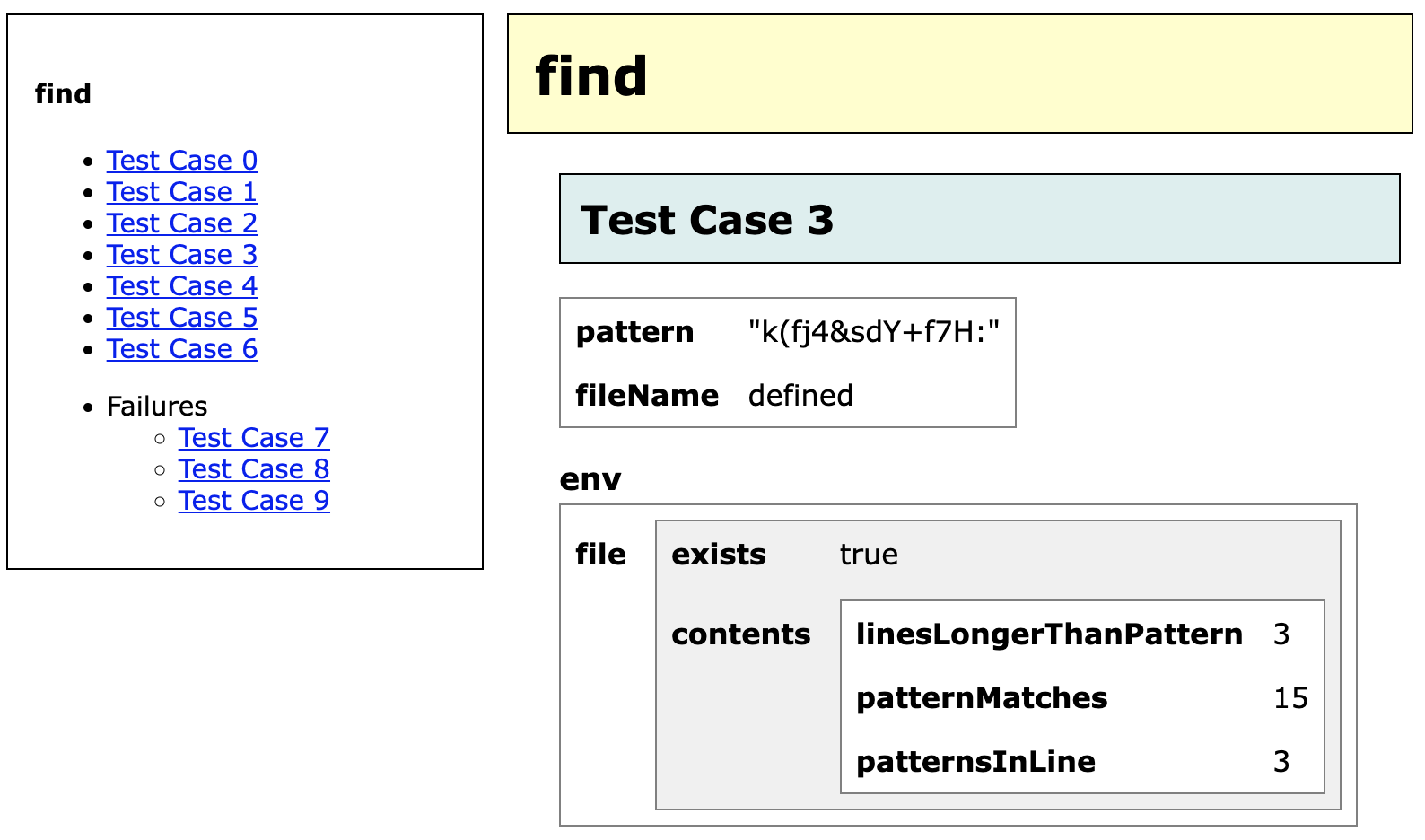
Don't particularly care for this report format? You can define and apply your own presentation format using the TestDefToHtmlFilter class.
Creating JUnit/TestNG Tests
Transforming test cases into JUnit or TestNG code is a capability that is built into the tcases command. How does it work? Just add the -J option, and Tcases will automatically writes test case definitions in the form of Java code for a JUnit test. The same code works for TestNG, too.
Here's a simple example. Try out these commands:
> cd docs/examples/xml
> tcases -J < find-Input.xml
Here's what you'll see printed to standard output: each test case definition has been transformed into a @Test method. The name of the method is based on the Function name. And the Javadoc comments describe the input values for this test case. Similarly, all input value assignments are shown in the body of the method. Otherwise, the body of the method is empty, waiting for the implementation to be filled in by you.
* Tests {@link Examples#find find()} using the following inputs.
* <P>
* <TABLE border="1" cellpadding="8">
* <TR align="left"><TH colspan=2> 0. find (Success) </TH></TR>
* <TR align="left"><TH> Input Choice </TH> <TH> Value </TH></TR>
* <TR><TD> pattern.size </TD> <TD> empty </TD> </TR>
* <TR><TD> pattern.quoted </TD> <TD> yes </TD> </TR>
* <TR><TD> pattern.blanks </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> pattern.embeddedQuotes </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> fileName </TD> <TD> defined </TD> </TR>
* <TR><TD> file.exists </TD> <TD> yes </TD> </TR>
* <TR><TD> file.contents.linesLongerThanPattern </TD> <TD> one </TD> </TR>
* <TR><TD> file.contents.patterns </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> file.contents.patternsInLine </TD> <TD> (not applicable) </TD> </TR>
* </TABLE>
* </P>
*/
@Test
public void find_0()
{
// Given...
// pattern.size = empty
// pattern.quoted = yes
// pattern.blanks = (not applicable)
// pattern.embeddedQuotes = (not applicable)
// fileName = defined
// file.exists = yes
// file.contents.linesLongerThanPattern = one
// file.contents.patterns = (not applicable)
// file.contents.patternsInLine = (not applicable)
// When...
// Then...
}
...
For failure test cases, the Javadoc highlights the single invalid value that defines the case.
/**
* Tests {@link Examples#find find()} using the following inputs.
* <P>
* <TABLE border="1" cellpadding="8">
* <TR align="left"><TH colspan=2> 6. find (<FONT color="red">Failure</FONT>) </TH></TR>
* <TR align="left"><TH> Input Choice </TH> <TH> Value </TH></TR>
* <TR><TD> pattern.size </TD> <TD> empty </TD> </TR>
* <TR><TD> pattern.quoted </TD> <TD> <FONT color="red"> unterminated </FONT> </TD> </TR>
* <TR><TD> pattern.blanks </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> pattern.embeddedQuotes </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> fileName </TD> <TD> defined </TD> </TR>
* <TR><TD> file.exists </TD> <TD> yes </TD> </TR>
* <TR><TD> file.contents.linesLongerThanPattern </TD> <TD> many </TD> </TR>
* <TR><TD> file.contents.patterns </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> file.contents.patternsInLine </TD> <TD> (not applicable) </TD> </TR>
* </TABLE>
* </P>
*/
@Test
public void find_6()
{
// Given...
...
// When...
// Then...
}
...
The -J option is most useful when the System corresponds to a class and each Function corresponds to a class method to be tested. Accordingly, the Javadoc includes an @link to the method-under-test, as shown above. You can customize the form of this @link by defining either the class parameter or the system parameter. For example, if you use the options "-J -p class=MyClass", then the output looks like this:
* Tests {@link MyClass#find find()} using the following inputs.
* <P>
* <TABLE border="1" cellpadding="8">
* <TR align="left"><TH colspan=2> 0. find (Success) </TH></TR>
* <TR align="left"><TH> Input Choice </TH> <TH> Value </TH></TR>
* <TR><TD> pattern.size </TD> <TD> empty </TD> </TR>
* <TR><TD> pattern.quoted </TD> <TD> yes </TD> </TR>
* <TR><TD> pattern.blanks </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> pattern.embeddedQuotes </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> fileName </TD> <TD> defined </TD> </TR>
* <TR><TD> file.exists </TD> <TD> yes </TD> </TR>
* <TR><TD> file.contents.linesLongerThanPattern </TD> <TD> one </TD> </TR>
* <TR><TD> file.contents.patterns </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> file.contents.patternsInLine </TD> <TD> (not applicable) </TD> </TR>
* </TABLE>
* </P>
*/
@Test
public void find_0()
{
// Given...
...
// When...
// Then...
}
...
Alternatively, if you use the options "-J -p system=MySystem", then the output looks like this:
* Tests MySystem using the following inputs.
* <P>
* <TABLE border="1" cellpadding="8">
* <TR align="left"><TH colspan=2> 0. find (Success) </TH></TR>
* <TR align="left"><TH> Input Choice </TH> <TH> Value </TH></TR>
* <TR><TD> pattern.size </TD> <TD> empty </TD> </TR>
* <TR><TD> pattern.quoted </TD> <TD> yes </TD> </TR>
* <TR><TD> pattern.blanks </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> pattern.embeddedQuotes </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> fileName </TD> <TD> defined </TD> </TR>
* <TR><TD> file.exists </TD> <TD> yes </TD> </TR>
* <TR><TD> file.contents.linesLongerThanPattern </TD> <TD> one </TD> </TR>
* <TR><TD> file.contents.patterns </TD> <TD> (not applicable) </TD> </TR>
* <TR><TD> file.contents.patternsInLine </TD> <TD> (not applicable) </TD> </TR>
* </TABLE>
* </P>
*/
@Test
public void find_0()
{
// Given...
...
// When...
// Then...
}
...
And, if you'd rather not have input value assignments shown in the test method body, you can exclude them by adding the option
Using the -J option also changes the default output file for the tcases command. Normally, when you're working with a Tcases project, generated test case definitions are written by default to a file named ${myProjectName}-Test.xml. But with -J, the generated @Test methods are written by default to a file named ${myProjectName}Test.java. Exception: if your ${myProjectName} is not a valid Java class identifier, a slightly modified form of the project name is used instead.
For example, the following command will write generated test definitions in the form of @Test methods to a file named findTest.java
Using XSLT Transforms
The JUnit output transform is implemented using XSLT templates. If you've created your own XSLT stylesheet to transform test case definitions, you can apply it using the -x option.
For example, the following command will still send its output to the default test case definition file for the project, ${myProjectName}-Test.xml. But first it transforms the standard test case definition document using the XSLT stylesheet in the myStylesheet.xml file.
Because the transformed document is a different kind of document, you'll usually want to write it to a different type of file, using the -f option.
If your XSLT stylesheet uses parameters, you can assign them values using one or more instances of the -p option. For example:
Using Output Annotations
For a transformation to produce concrete test cases, sometimes the basic information in the input model — functions, variables, and values — is not enough. You need to add extra information that is not important for generating the test cases but is necessary to form the final output. That's what output annotations are for.
An output annotation is a special property setting — a name-value pair — that you can add to various elements of a system input definition. It has no effect on test cases that Tcases generates. But Tcases will accumulate output annotations and attach them to the resulting system test definition document. In addition, Tcases will automatically attach output annotations listing the properties of each TestCase. From there, your XSLT output transform can use these output annotations to complete tests cases in their final form.
Example: Generating test code
For an example of how this works, consider the following input model for a graphics function involving shapes with different properties, such as size and color.
<Function name="addShape">
<Input>
<Var name="Type">
<Value name="SQUARE"/>
<Value name="CIRCLE"/>
<Value name="LINE"/>
</Var>
<Var name="Size">
<Value name="1"/>
<Value name="10"/>
<Value name="100"/>
</Var>
<Var name="Color">
<Value name="red"/>
<Value name="green"/>
<Value name="blue"/>
</Var>
</Input>
</Function>
</System>
Suppose we wanted to transform test cases generated from this input model into executable code. To do so, we annotate this input model with extra Has elements. Each Has element defines an output annotation with a name and a value.
For example, let's add the following output annotations.
<Function name="addShape">
<!-- Function annotations -->
<Has name="pageType" value="Page"/>
<Has name="pageName" value="page"/>
<Has name="pageValue" value="new Page()"/>
<Input>
<Var name="Type">
<!-- Variable binding annotations -->
<Has name="varType" value="Shape"/>
<Has name="varName" value="shape"/>
<Has name="varEval" value="new Shape"/>
<Value name="SQUARE"/>
<Value name="CIRCLE"/>
<Value name="LINE"/>
</Var>
<Var name="Size">
<!-- Variable binding annotations -->
<Has name="varType" value="int"/>
<Has name="varName" value="size"/>
<Has name="varApply" value="setSize"/>
<Value name="1"/>
<Value name="10"/>
<Value name="100"/>
</Var>
<Var name="Color">
<!-- Variable binding annotations -->
<Has name="varType" value="String"/>
<Has name="varName" value="color"/>
<Has name="varApply" value="setColor"/>
<Value name="red"/>
<Value name="green"/>
<Value name="blue"/>
</Var>
</Input>
</Function>
</System>
Now when we run tcases, we see that these output annotations have been propagated to the generated test cases.
<Function name="addShape">
<!-- Function annotations -->
<Has name="pageName" value="page"/>
<Has name="pageType" value="Page"/>
<Has name="pageValue" value="new Page()"/>
<TestCase id="0">
<!-- Function annotations -->
<Has name="pageName" value="page"/>
<Has name="pageType" value="Page"/>
<Has name="pageValue" value="new Page()"/>
<Input type="arg">
<Var name="Type" value="SQUARE">
<!-- Variable binding annotations -->
<Has name="varEval" value="new Shape"/>
<Has name="varName" value="shape"/>
<Has name="varType" value="Shape"/>
</Var>
<Var name="Size" value="1">
<Has name="varApply" value="setSize"/>
<Has name="varName" value="size"/>
<Has name="varType" value="int"/>
</Var>
<Var name="Color" value="red">
<Has name="varApply" value="setColor"/>
<Has name="varName" value="color"/>
<Has name="varType" value="String"/>
</Var>
</Input>
</TestCase>
...
</Function>
</TestCases>
So, what's so special about these annotated test cases? In one sense, nothing — they describe exactly the same set of input variable choices as before. But they set the stage for the next phase of test case generation, using an output transform. For example, by applying annotations-Transform.xsl (shown here and in the docs/examples/xml directory), we can use these annotations to transform the system test definition document into executable source code that looks like this:
@Test
public void test_addShape_0() {
Page page = new Page();
Shape shape = new Shape(SQUARE);
int size = 1;
shape.setSize(size);
String color = "red";
shape.setColor(color);
page.addShape(shape);
}
...
}
How it works
We can add the following kinds of output annotations.
- System annotations are created by adding a Has element to a System element. Each system annotation is transferred to the output document by applying it to the top-level TestCases element. In addition, each system annotation is added to all Function and TestCase elements.
- Function annotations are created by adding a Has element to a Function element. Each function annotation is transferred to the output document by applying it to the corresponding output Function element. In addition, each function annotation is added to all TestCase elements within its scope. Annotations for a Function override any annotations of the same name defined for the System.
- Variable binding annotations are created by adding a Has element to a Var or a VarSet element. You can also create a variable binding annotation that applies to a group of variables by adding a Has element to an Input. Or you can create a variable binding annotation that is value-specific by adding a Has element to a Value element. Each variable binding annotation is transferred to the output document by applying it to all Var elements within its scope. Annotations for a Value override any annotations of the same name defined for a Var, which override annotations for a VarSet, which override annotations for an Input.
Why are system and function annotations also copied to all of the associated TestCase elements? Because such annotations can have multiple purposes. In some cases, these annotations can be used to form the corresponding level of the transformed output document. In other cases, these annotations can be used to define system- or function-wide defaults for values used to form individual concrete test cases.
Property annotations
The value properties that characterize a test case can be useful meta-data for further transformations of test case data. For this reason, Tcases automatically attaches them to each generated TestCase using a special output annotation named "properties".
For example, if we add the following value properties to our input model:
<Function name="addShape">
<!-- Function annotations -->
<Has name="pageType" value="Page"/>
<Has name="pageName" value="page"/>
<Has name="pageValue" value="new Page()"/>
<Input>
<Var name="Type">
<!-- Variable binding annotations -->
<Has name="varType" value="Shape"/>
<Has name="varName" value="shape"/>
<Has name="varEval" value="new Shape"/>
<Value name="SQUARE"/>
<Value name="CIRCLE"/>
<Value name="LINE" property="1D" />
</Var>
<Var name="Size">
<!-- Variable binding annotations -->
<Has name="varType" value="int"/>
<Has name="varName" value="size"/>
<Has name="varApply" value="setSize"/>
<Value name="1"/>
<Value name="10"/>
<Value name="100" property="Large"/>
</Var>
<Var name="Color">
<!-- Variable binding annotations -->
<Has name="varType" value="String"/>
<Has name="varName" value="color"/>
<Has name="varApply" value="setColor"/>
<Value name="red"/>
<Value name="green"/>
<Value name="blue"/>
</Var>
</Input>
</Function>
</System>
Then when we run tcases, we see the following "properties" annotation added to the output:
<Function name="addShape">
...
<TestCase id="2">
<Has name="pageName" value="page"/>
<Has name="pageType" value="Page"/>
<Has name="pageValue" value="new Page()"/>
<Has name="properties" value="1D,Large"/>
<Input type="arg">
<Var name="Type" value="LINE">
<Has name="varEval" value="new Shape"/>
<Has name="varName" value="shape"/>
<Has name="varType" value="Shape"/>
</Var>
<Var name="Size" value="100">
<Has name="varApply" value="setSize"/>
<Has name="varName" value="size"/>
<Has name="varType" value="int"/>
</Var>
<Var name="Color" value="blue">
<Has name="varApply" value="setColor"/>
<Has name="varName" value="color"/>
<Has name="varType" value="String"/>
</Var>
</Input>
</TestCase>
</Function>
</TestCases>
Further Reference
Want more technical details about Tcases? Here are links to some additional information.
- The find command example (XML, JSON)
- The tcases command line
- Document schemas
- Related testing techniques